A couple of weeks ago, I published a first article on code clones based on a paper I wrote a couple of terms back in my undergrad. If you haven’t read that one yet, give it a read first. In this part I focus on the different algorithmic approaches that can be used to detect code clones. And once more: All the stuff below is based on the German paper I wrote for a class on Software Quality, which is in turn based on the publications referenced in the paper and at the bottom of this page. Any gross oversimplifications and inaccuracies are entirely my fault.
So, what we have from the last post is an understanding of what code clones are, what different types of clones there are, and an understanding that we should try to avoid them if possible. Now, let’s take a look at how to detect such code clones in a code base (short of hiring someone to read code and just flag clones manually).
To do this we will consider four different approaches in increasing order of abstraction.

After all code is just text, right? – Text-based
This is the most obvious approach: Just take two snippets of code and compare them line-by-line. The results of this are already pretty good, but we are going to get a lot of false negatives: For example would you still consider two fragments to be clones if the only difference was that one was indented with tabs and the other with spaces? How about if the only difference was comments? To account for this, before doing the line-wise comparison, a normalized version of the program is computed.
The naive approach of comparing every line with every other line has a slight performance issue when we get to lager code bases, but this can be easily remedied by computing some kind of hash of the line first and only doing the full comparison if the hashes are identical.
But code is different from prose, right? – Tokens
Another possible way to approach the problem is using a Lexer to turn the source code into a sequence of tokens. These sequences of tokens can then be efficiently compared by using a suffix tree (in linear time in fact). The suffix tree also makes it easy to find approximate matches which we need to do to find Type-III clones.
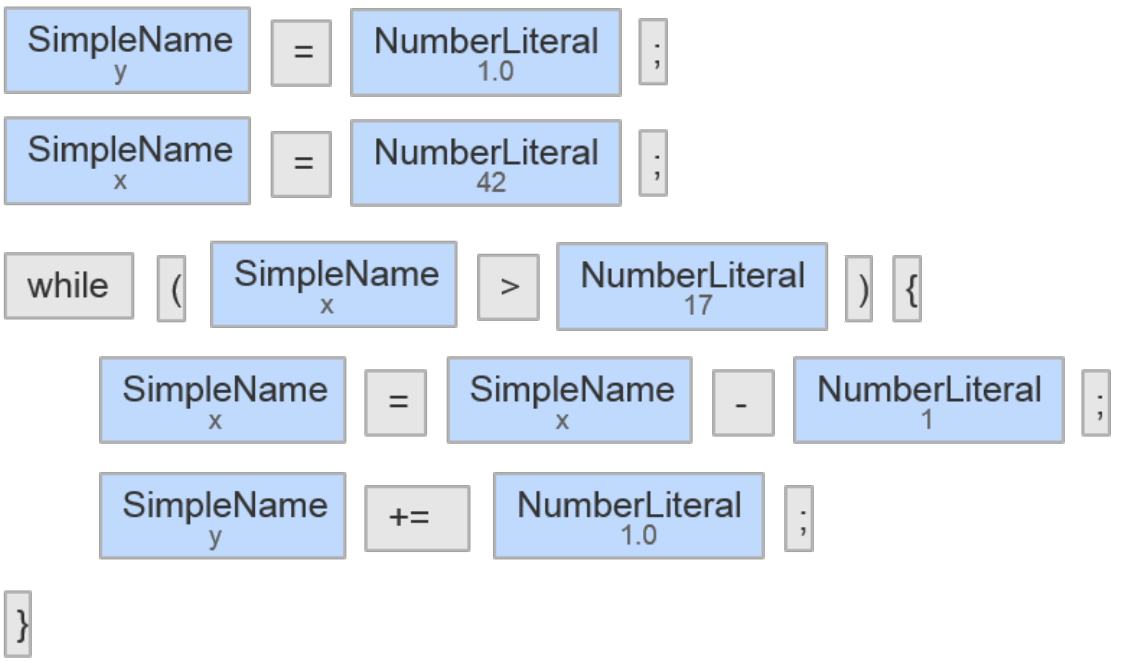
Let’s go up a level! – Abstract Syntax Tree
One of the problems of the two approaches discussed so far is that they don’t respect syntactical boundaries (such as classes or methods in the case of OOP), leading to clones that span across several such units. Those clones are however not really relevant to developers, since removing them is often not possible. With relatively little effort we could do post-processing to remove those results from the output of our algorithms.
For the third technology this is no longer necessary since we do not stop with the token stream but instead pass this token stream on to a parser for the language we are looking at. The parser in turn outputs an Abstract Syntax Tree (AST). When we look for code clones, we look for similar subtrees in the ASTs.
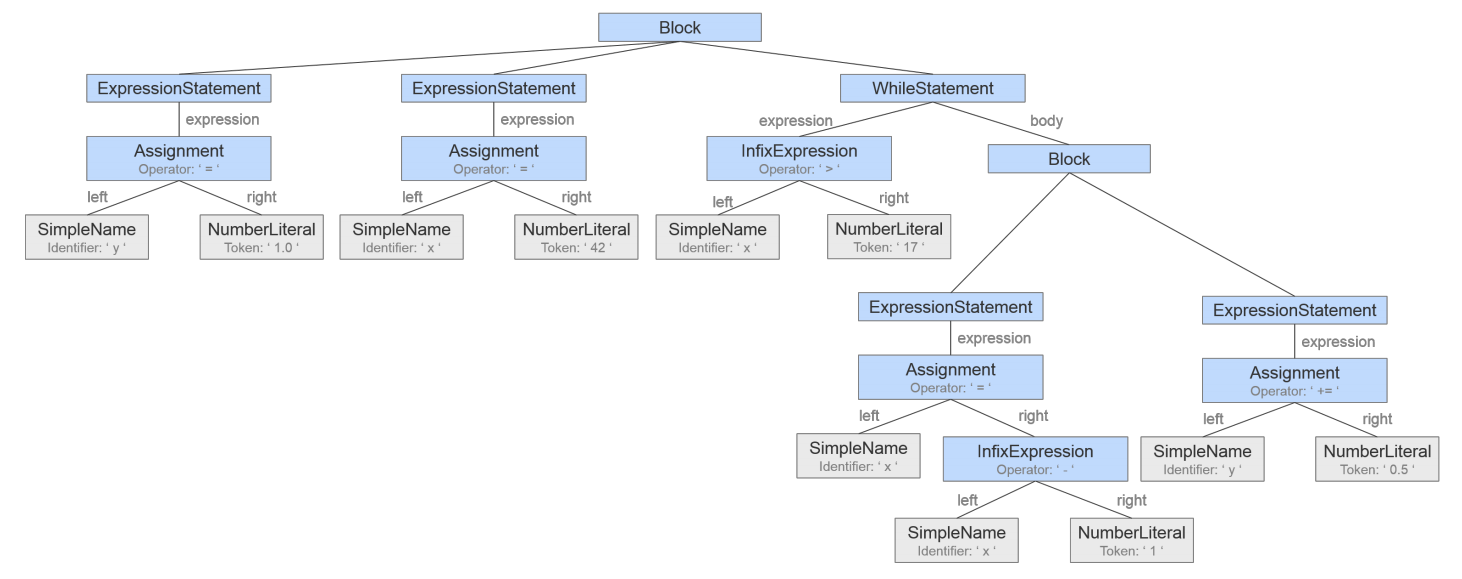
Free to reorder – Program Dependency Graph
The last approach we are going to take a look at is based on Program Dependency Graphs (PDG). What all the previous methods have in common is that they consider the order of statements when deciding if two fragments are code clones. But there is almost always some wiggle-room for reordering statements without changing any functionality. And even after these changes, the code is often still similar enough to be considered a clone. Let’s take a look at an example again:

A, B and C do the exact same thing, but D does not. So there are obviously certain rules we must follow: Our reorderings must preserve the dependencies between computations and also preserve the control flow. By moving the assignment to x before the computation of y in fragment D we violated this rule.
When we represent all these dependencies at the same time, we obtain the PDG. Control structures and assignments form the nodes, while the dependencies are represented by different types of edges. Let’s take a look at such a PDG:
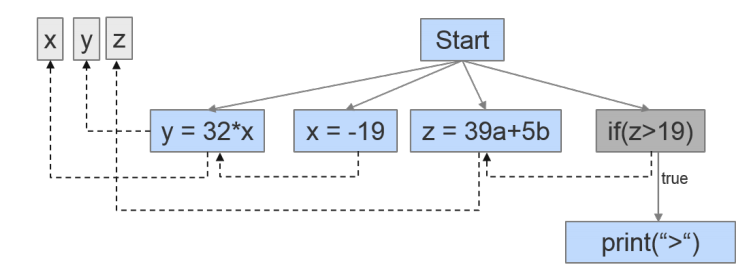
Now to find fragments that are clones we look for subgraphs that are isomorphic to each other. This is also one of the things that makes this approach really hard (NP-hard to be precise 😉 ) so in practice approximative algorithms are used. One of the strengths of this approach is unfortunately also a potential downside: It is quite a strong abstraction from the source code, so the algorithm might flag code fragments that appear to be very different when considering their source code, leading to results which are not interesting for developers.
Which one is best?
The answer here, as almost always, is: It depends! The standard metrics for this kind of evaluation are recall and precision. While recall measures how many clones that were actually in there were also detected, precision measures how many of the reported clones are actually clones. How do we know what are actual clones? We need to ask humans to identify those.
In a study[BKA+07] 8 programs (4 in Java and 4 in C) where analyzed with different detection algorithms (among others all of the ones described above). A 30’000ft summary of their findings would be that both text-based and token-based approaches behave very similar. They outperform AST-based approaches when it comes to recall, but are worse when it comes to precision. One of the tools that was tested was based on PDG and generally didn’t perform too good except for Type-III clones.
I wanna know more!
Apart from reading the sources below (maybe starting with Kosche’s survey), I can really recommend this talk Nicholas Kraft gave at Google a couple of years ago:
All of this is a very high-level summary, for an in-depth look that also includes citations etc. take a look at the paper I wrote (German only unfortunately) or (probably even better) straight at the papers I cited. I’d like to end this with a big Thank You to Elmar Jürgens, the advisor for my seminar who helped me tremendously with corrections and advice for the German version of the paper.
Where are your sources?
[BKA+07] Stefan Bellon, Rainer Koschke, Giuliano Antoniol, Jens Krinke, and Ettore Merlo. Comparison and evaluation of clone detection tools. Software Engineering, IEEE Transactions on, 33(9):577–591, 2007.
[BYM+98] Ira D Baxter, Andrew Yahin, Leonardo Moura, Marcelo Sant Anna, and Lorraine Bier. Clone detection using abstract syntax trees. In Software Maintenance, 1998. Proceedings., International Conference on, pages 368–377. IEEE, 1998.
[DJH+08] Florian Deissenboeck, Elmar Juergens, Benjamin Hummel, Stefan Wagner, Benedikt Mas y Parareda, and Markus Pizka. Tool support for continuous quality control. Software, IEEE, 25(5):60–67, 2008.
[DRD99] Stéphane Ducasse, Matthias Rieger, and Serge Demeyer. A language independent approach for detecting duplicated code. In Software Maintenance, 1999.(ICSM’99) Proceedings. IEEE International Conference on, pages 109–118. IEEE, 1999.
[JDHW09] Elmar Juergens, Florian Deissenboeck, Benjamin Hummel, and Stefan Wagner. Do code clones matter? In Proceedings of the 31st International Conference on Software Engineering, pages 485–495. IEEE Computer Society, 2009.
[KBLN04] Miryung Kim, Lawrence Bergman, Tessa Lau, and David Notkin. An ethnographic study of copy and paste programming practices in oopl. In Empirical Software Engineering, 2004. ISESE’04. Proceedings. 2004 International Symposium on, pages 83–92. IEEE, 2004.
[Kos07] Rainer Koschke. Survey of research on software clones. 2007.
[Kri01] Jens Krinke. Identifying similar code with program dependence graphs. In Reverse Engineering, 2001. Proceedings. Eighth Working Conference on, pages 301–309. IEEE, 2001.
[MNK+02] Akito Monden, Daikai Nakae, Toshihiro Kamiya, Shin-ichi Sato, and K-i Matsumoto. Software quality analysis by code clones in industrial legacy software. In Software Metrics, 2002. Proceedings. Eighth IEEE Symposium on, pages 87–94. IEEE, 2002.