I’ve been keeping very busy since I moved to Norway for my internship, but today finally was one of those rainy October Sundays so I had the time to sit down and finally finish this post which I have been meaning to write for a little over a year but never got around to. Well, here it goes: All the stuff below is based on the German paper I wrote for this class, which is in turn based on the publications referenced in the paper and at the bottom of this page. Any gross oversimplifications and inaccuracies are entirely my fault.
Way back in the 6th semester of my Bachelor’s at TUM I had the opportunity to take a seminar class focusing on software quality. The general idea was to get a better understanding of what good code quality is and go beyond the notion of “a good developer know good code when they see it” and also to investigate if there are metrics that might be interesting. My topic was code clones and I was working under the supervision of a researcher at TUM who has published on exactly this topic.
What is a Code Clone?
First up, let’s define what we mean by Code Clone. One definition seems immediately obvious:
“Code Clones are segments of code that are similar according to some definition of similarity.” – Ira Baxter
However, that doesn’t really help us if we want a computer to analyze code to find clones. So let’s take a look at a definition used in literature that we can throw at a computer:
- Type I clones: two segments are clones if they are identical save for whitespace and comments.
- Type II clones: allow for consistent renaming of identifiers and changing the values of literals.
- Type III clones: several statements may be different between clones.
I guess it is example time!

Code fragments A and B obviously form a Type I clone – they are identical save for whitespace and comments. A/C and B/C are Type II clones, the only difference is that someone decided to switch x and y. For A/D, B/D and C/D it is a different story: Here the method call is added, making it a Type III clone.
The definition of Type III clones seems a bit vague, so there are several ways to make this definition more exact e.g. fixing an upper threshold for the edit distance between two clone candidates. Another issue is that according to the definition above, even if just one line is copied, we already have a code clone, which doesn’t make sense from a practical point of view. So usually a minimum length requirement for code clones is added to fix this issue.
Why are developers cloning code?
There are a lot of different reasons, but they can be roughly divided into forced duplication and avoidable duplication. The first category includes cases where the programming language used does not allow for the desired abstraction: A classical example would be that Multiple Implementation Inheritance is not supported in Java or C#. While in a language that fully supports it there might be ways to avoid code clones the same thing may not be possible in those languages. Another example that falls into this category are Cross-Cutting-Concerns (e.g. logging or Null-Checks for all reference parameters). If the language does not support aspect-oriented programming, this can be another cause of forced duplication.
The other group of reasons leads to avoidable duplication. The most obvious case here is that the programmers lack the necessary skills and knowledge of a programming language to avoid duplication despite the language offering appropriate abstractions. Another big reason is developers using Copy&Paste as their methodology for developing: We’ve all been there: Instead of coming up with entirely new code, code somewhere else in the program that does something similar is simply copied over and then tweaked until it fulfills the new requirements. There’s absolutely nothing wrong with that, but the next step should be thinking about possible ways to reuse this fragment of code and remove the duplication. But alas, software development typically happens under really tight deadlines: Just leaving the copied code in there instead of properly refactoring is faster than doing it by the book. The “only” disadvantage is that it accrues technical debt.

Does it even matter?
Literature argues that code clones have two main negative effects: Increased maintenance and increased number of bugs. Increased maintenance seems obvious: If I copied a piece of code to 25 places and I need to change something, I need to change it in 25 places now. And if I forget two or three of those – bang – I just introduced a new bug! Obvious doesn’t mean correct though – so, time to break out the science:
- [MNK+02] considered the amount of changes made to a module compared to how many clones it contains. The results were clear, the modules with more code clones had a significantly higher revision count.
- [JDHW09] looked at five big software systems and found that 52% of clone groups are inconsistent (i.e. not identical, Type III). This might be on purpose, but after interviewing developers, they found only about 75% of these inconsistencies were desired. The remaining 25% were by mistake. Out of those 50% also lead the software to visibly misbehave.
You got any real-world examples?
In the paper, I look at different algorithms to detect code clones next, but I’m gonna leave that for another rainy Sunday. Instead, I want to share some results about real world projects obtained with ConQAT, an Eclipse-based software tool that among a ton of other things also supports analysis of code clones. All five projects are Open-Source and implemented in Java.
First of all, let’s take a look at Type I/II clones:
| Project | Description | kLoC total | cloned |
|---|---|---|---|
| Art of Illusion | 3D modelling and rendering | 121 | 24 (26.9%) |
| ArgoUML | UML tool | 363 | 38 (10.3%) |
| FreeCol | turn-based strategy game | 184 | 10 (5.4%) |
| FreeMind | mindmapping tool | 108 | 5 (4.5%) |
| JUnit | Unit testing | 16 | 0.4 (2.9%) |
What’s important to keep in mind here, is that this of course only an upper bound on the number of actual clones since there are definitely some false-positives. Also, the application domains for all of them are very different.
However even with that caveat the difference in the number of clones becomes very obvious. Next, let’s take a closer look at the clones: How big are they and in how many places can the same piece of code be found?
| Project | max. normalized length (LOC) | max. involved instances |
|---|---|---|
| Art of Illusion | 302 | 10 |
| ArgoUML | 176 | 20 |
| FreeCol | 52 | 16 |
| FreeMind | 74 | 5 |
| JUnit | 21 | 2 |
The trend that we saw before does seem to continue: While JUnit still has the best values, Art of Illusion continues to have very high numbers in both dimensions. Let’s also take a look at the longest clones in Art of Illusion and ArgoUML: For
Art of Illusion the two involved classes only differ in 12.5% of their code. In the case of ArgoUML the only difference is the name of the involved classes, hinting at a very easy fix for this issue.
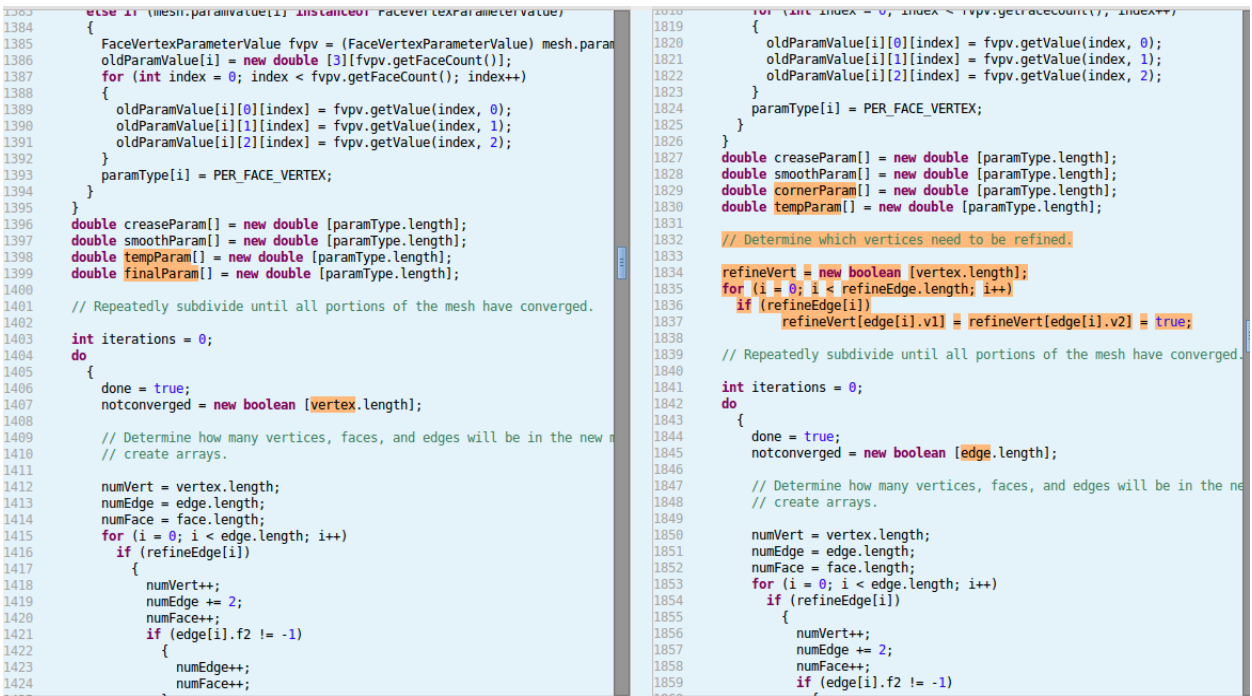
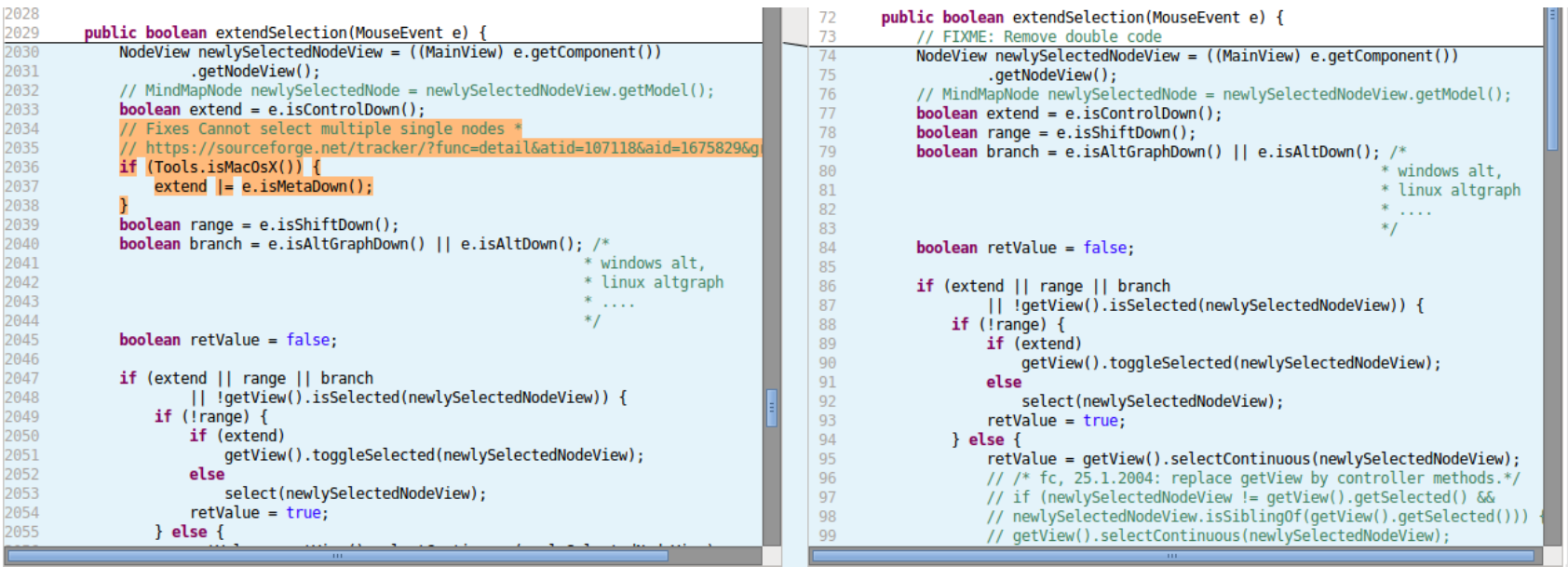
The results are really similar for Type III clones, so I just want to highlight one example from FreeMind, that supports the argument that development by copy&paste can lead to bugs.
All of this is a very high-level summary, for an in-depth look that also includes citations etc. take a look at the paper I wrote (German only unfortunately) or (probably even better) straight at the papers I cited. I’d like to end this with a big Thank You to Elmar Jürgens, the advisor for my seminar who helped me tremendously with corrections and advice for the German version of the paper.
Where are your sources?
[AOI] Art of Illusion project page. http://www.artofillusion.org/.
[ARG] ArgoUML project page. http://argouml.tigris.org/.
[BKA+07] Stefan Bellon, Rainer Koschke, Giuliano Antoniol, Jens Krinke, and Ettore Merlo. Comparison and evaluation of clone detection tools. Software Engineering, IEEE Transactions on, 33(9):577–591, 2007.
[BYM+98] Ira D Baxter, Andrew Yahin, Leonardo Moura, Marcelo Sant Anna, and Lorraine Bier. Clone detection using abstract syntax trees. In Software Maintenance, 1998. Proceedings., International Conference on, pages 368–377. IEEE, 1998.
[DJH+08] Florian Deissenboeck, Elmar Juergens, Benjamin Hummel, Stefan Wagner, Benedikt Mas y Parareda, and Markus Pizka. Tool support for continuous quality control. Software, IEEE, 25(5):60–67, 2008.
[DRD99] Stéphane Ducasse, Matthias Rieger, and Serge Demeyer. A language independent approach for detecting duplicated code. In Software Maintenance, 1999.(ICSM’99) Proceedings. IEEE International Conference on, pages 109–118. IEEE, 1999.
[FREa] FreeCol project page. http://www.freecol.org/.
[FREb] FreeMind project page. http://freemind.sourceforge.net/wiki/index.php/Main_Page.
[JDHW09] Elmar Juergens, Florian Deissenboeck, Benjamin Hummel, and Stefan Wagner. Do code clones matter? In Proceedings of the 31st International Conference on Software Engineering, pages 485–495. IEEE Computer Society, 2009.
[JUN] JUnit Projektseite. http://junit.org/.
[KBLN04] Miryung Kim, Lawrence Bergman, Tessa Lau, and David Notkin. An ethnographic study of copy and paste programming practices in oopl. In Empirical Software Engineering, 2004. ISESE’04. Proceedings. 2004 International Symposium on, pages 83–92. IEEE, 2004.
[Kos07] Rainer Koschke. Survey of research on software clones. 2007.
[Kri01] Jens Krinke. Identifying similar code with program dependence graphs. In Reverse Engineering, 2001. Proceedings. Eighth Working Conference on, pages 301–309. IEEE, 2001.
[MNK+02] Akito Monden, Daikai Nakae, Toshihiro Kamiya, Shin-ichi Sato, and K-i Matsumoto. Software quality analysis by code clones in industrial legacy software. In Software Metrics, 2002. Proceedings. Eighth IEEE Symposium on, pages 87–94. IEEE, 2002.
2 thoughts on “Copy Pasta and its effects on Code Quality (a.k.a. Term Paper on Code Clones)”